I shipped Ragbot v3.5 today, the third release of my open-source conversational AI project in about a month. It follows v3.3 (local Gemma 4 as first-class) and v3.4 (the next-major-features release). The right way to read them is as one architectural arc. Ragbot stopped being a RAG assistant and became a conversational reference runtime.
Why three releases are one shift
The center of gravity in chat-with-tools products has moved. The 2024-paradigm shape was chat with retrieval. The 2026-paradigm shape is stateful, tool-using agents with durable memory, governed execution, and async background work. The Model Context Protocol (MCP) went from research curiosity to industry-default infrastructure at 97M monthly SDK downloads and 5,800+ public servers. SKILL.md, the agent-skills file format Anthropic introduced with Claude Code, is now adopted by Codex CLI, Gemini CLI, GitHub Copilot, and Cursor. Memory architectures run three layers (vector, graph, session) in production deployments. Observability is a buying criterion, not polish. Local inference on Apple Silicon crossed the credibility threshold with the Ollama 0.19 MLX backend.
Ragbot before v3.3 read clean and ran well, but it looked like a 2024 product to anyone who had seen the category’s new shape. The arc from v3.3 to v3.5 closes that gap. Each release carries a different load-bearing piece. v3.3 proved that local-first deployment was viable as a default, not a curiosity. v3.4 shipped the architectural moves that make the conversational runtime credible. v3.5 cleaned up the substrate so the runtime is production-coherent, not just demo-ready.
The design instruction came from outside. VILA-Lab’s Dive into Claude Code analysis (source) found that 1.6% of a working conversational AI runtime is the model’s decision logic and 98.4% is deterministic infrastructure: permission gates, context management, tool routing, recovery mechanisms. That ratio is the design instruction. The three releases build the 98.4% for the conversational primitive.
v3.3: local Gemma 4 earns first-class status
v3.3 added a new ollama engine that ships Google’s Gemma 4 family (E4B, 26B MoE, 31B Dense) as first-class models alongside Anthropic, OpenAI, and Google. No API key. LiteLLM routes via the ollama_chat/ prefix. The Docker stack reaches host Ollama at host.docker.internal:11434 out of the box, and OLLAMA_API_BASE overrides it when Ollama runs elsewhere on the LAN.
The release also redesigned the model picker. A single rich dropdown replaced the three-step Provider → Category → Model cascade. Display names (Claude Opus 4.7, not claude-opus-4-7). Pinned and Recent at the top. Type-ahead search. ⌘K opens it globally. Capability badges for tier (Fast / Balanced / Powerful), context window, 🧠 thinking, 🏠 local. A new user-preferences API (/api/preferences/pinned-models, /api/preferences/recent-models) persists selections to ~/.synthesis/ragbot.yaml so the picker remembers across sessions. The thinking-effort control moved adjacent to the model so it renders only when the chosen model supports it; off-by-default for non-flagship models.
Two hygiene items round out v3.3. A bug fix: non-flagship GPT-5.x and Gemini models no longer return empty content on long-context RAG calls. The default reasoning_effort for those models is now the lowest declared mode, so the provider’s own reasoning default does not consume the entire output-token budget. And LiteLLM was pinned >=1.83.0 to exclude the compromised 1.82.7 / 1.82.8 range from the March 2026 supply-chain incident.
v3.3’s local-first work becomes load-bearing in v3.4: client-confidential workspaces route to local-only by default, and the cross-workspace synthesis story only works if local inference is good enough to keep that work in-network. v3.3 made local inference good enough.
v3.4: the conversational runtime
The single-turn prompt → retrieve → call LLM → return path is gone. In its place are eight visible capability moves that compose into one runtime shape: an agent loop, first-class MCP in both directions, an executable skills runtime, cross-workspace synthesis with visible confidentiality boundaries, durable memory beyond vector RAG, open-weights generalization, OpenTelemetry observability, and a coherent keyboard shortcut layer.
A hand-rolled agent loop
The agent can answer directly, dispatch retrieval, call a tool, run a skill, or fan out to sub-agents. I did not use a framework. No LangGraph, no CrewAI, no AutoGen. Those projects are open source and the patterns they document are worth studying as references; the reason for not depending on one is coupling. The deterministic plumbing (permission gates, context management, tool routing, recovery) is the differentiator, and putting that plumbing behind a framework’s abstraction would put the differentiator there with it. The Plan-and-Execute pattern (produce a plan, execute steps, replan on failure) is the default for compound questions; the lead-agent-with-sub-agents pattern handles parallel research across workspaces. The whole loop is plain state-machine code, debugged with a stepper and the existing test rig.
Permission gates fail closed at the tool boundary. Unknown tools deny by default. State checkpoints are durable; ragbot agent replay deterministically re-runs a session from any checkpoint, and a stable hash over {current_state, final_answer, step_results} flags regressions against the baseline. The chat-only no-tools mode remains available; the agent loop is opt-in per session.
MCP as a first-class peer
Ragbot is now both an MCP client and an MCP server. As a client, it implements all six MCP primitives (tools, resources, prompts, Roots, Sampling, Elicitation) plus MCP Tasks for long-running calls. Each primitive earns its place: Sampling lets an MCP server call back into Ragbot’s LLM, Elicitation supports human-in-the-loop interruption, Roots signal filesystem boundaries, and Tasks handle long calls that should not block the chat turn. Resources and Prompts cover the conventional cases.
As a server, Ragbot exposes its workspace surface to other MCP-aware agents. Claude Code, Cursor, ChatGPT desktop, Gemini CLI, and anything else that speaks the protocol can call into it. Five exposed tools (workspace_search, workspace_search_multi, document_get, skill_run, agent_run_start) plus three resources (ragbot://workspaces, ragbot://skills, ragbot://audit/recent). Bearer-token auth via ~/.synthesis/mcp-server.yaml with per-token allowed_tools glob filtering. The protocol is the integration layer.
Skills as an executable runtime
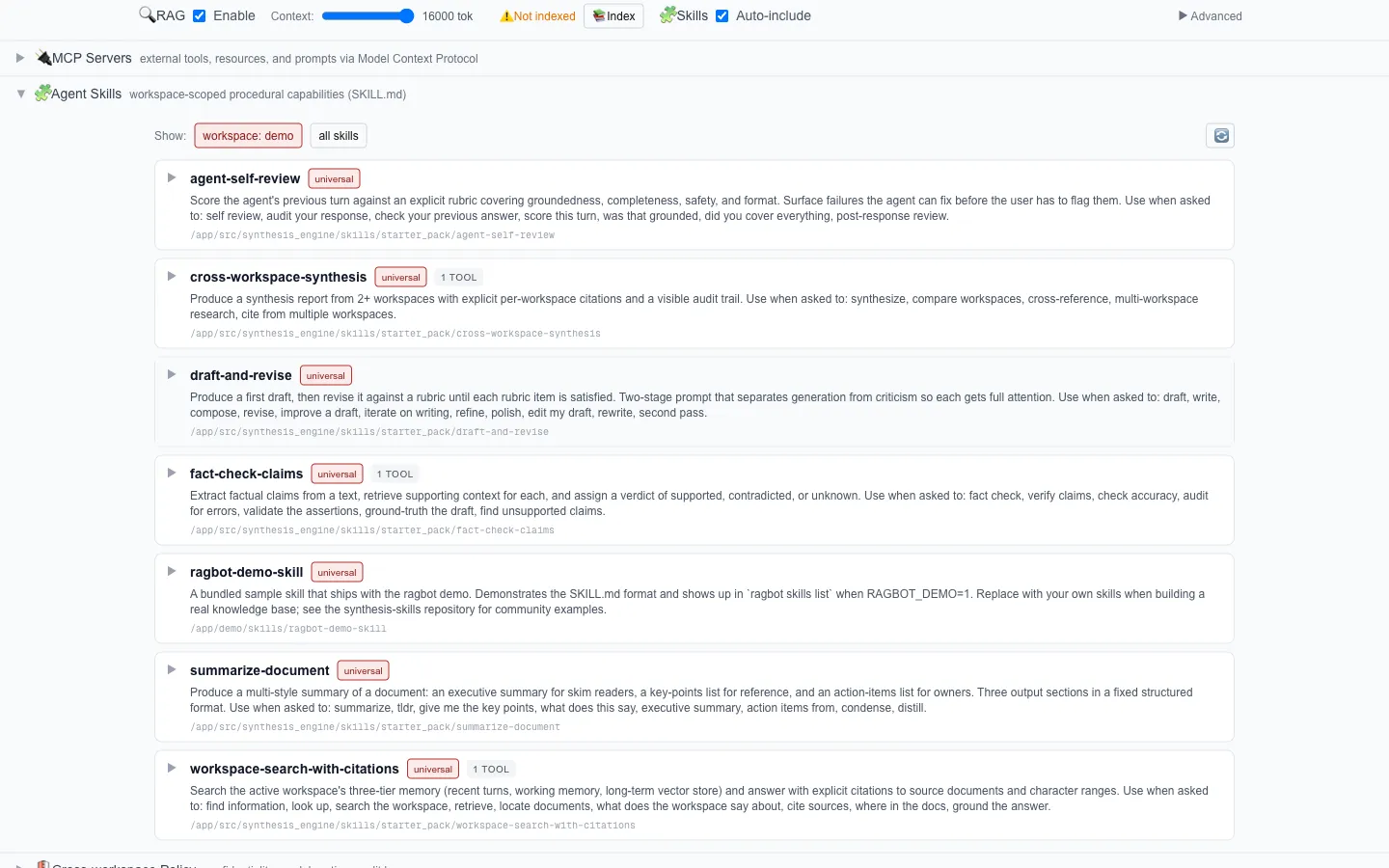
Before v3.4, Ragbot read skills as markdown and indexed them for RAG. v3.4 makes them executable in the progressive-disclosure model: names and descriptions in the system prompt, full body on selection, scripts and templates on tool call.
SKILL.md is now Ragbot’s native extensibility format. A skill written for Claude Code, Codex CLI, Cursor, or Gemini CLI runs on Ragbot without modification. Six starter skills ship in the box: workspace-search-with-citations, draft-and-revise, fact-check-claims, summarize-document, agent-self-review, and the brand-defining cross-workspace-synthesis. Skills discovery walks five roots in priority order with later-wins-on-name-collision, so operator-installed skills override built-ins. Ragbot is now the third compatible runtime for the SKILL.md format. The format’s value goes up as a third runtime adopts it; the cost of compatibility was low because the format was already designed for portability.
Cross-workspace synthesis
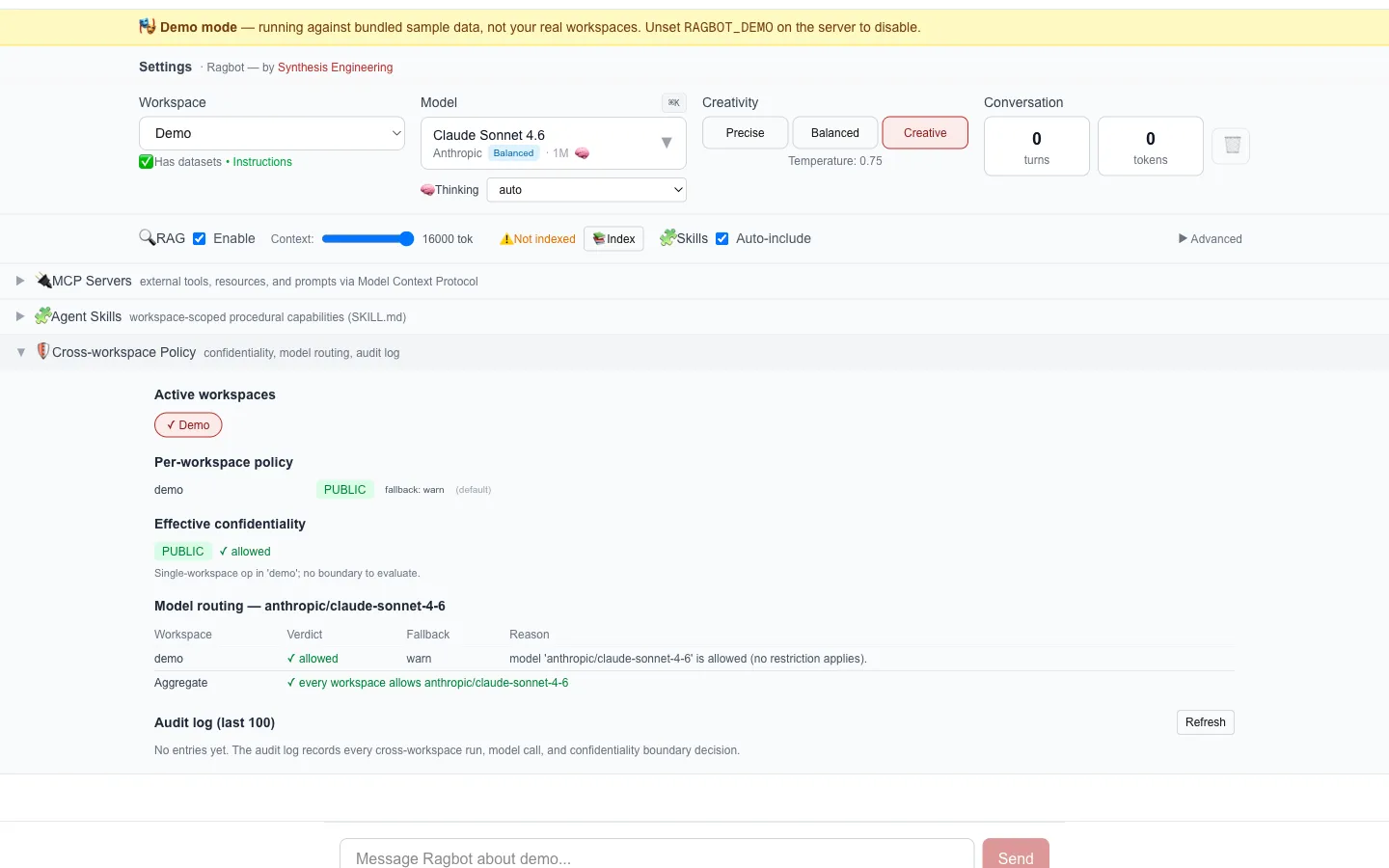
The synthesis-engineering thesis is that AI’s strengths (instant full-text search, cross-document synthesis, tireless consistency) should be designed for, not retrofitted onto human workflows. Multi-workspace synthesis is what falls out of that thesis when you take it seriously. Adding it to a single-workspace architecture later means rebuilding the policy layer; building it in from the start means the policy is just how routing and retrieval work.
Select two or more workspaces in the UI. Each carries a confidentiality tag: public, personal, client-confidential, or air-gapped. The effective confidentiality of a cross-workspace operation is the max of participants, so a mix of personal and client-confidential is treated as client-confidential end-to-end. Per-workspace routing.yaml files declare which models can be called for that workspace, and the agent runtime enforces the strictest applicable policy at every model call. Defaults are local-only for client-confidential, frontier for personal. This is where v3.3’s local-first work pays off; the policy is only credible because local inference is good enough to keep client-confidential work in-network.
Every cross-workspace operation appends to ~/.synthesis/cross-workspace-audit.jsonl with timestamp, workspaces involved, tools called, model used, and a redacted prompt summary. The log is O_APPEND-atomic on POSIX. A CTO plugging Ragbot into Datadog or Honeycomb can read the trail line by line.
The cross-workspace-synthesize starter skill walks the agent through per-workspace budget math, the four-level confidentiality strictness order, and the [workspace:document_id] citation format. Citations name the source workspace explicitly, so a reviewer can trace any synthesized fact back to its origin. The cross-workspace gate fires before retrieval, which means denied workspace combinations never read content. Fail-closed at the boundary; never closed-after-the-fact.
A worked example. With acme-news (tagged client-confidential) and acme-user (tagged personal) both selected, asking “what patterns appear in my AI consulting work this quarter?” produces a specific sequence. The agent loads each workspace’s routing.yaml. acme-news denies frontier models; acme-user allows them, so the intersection is local-only. The cross-workspace gate checks the pairwise mix. Allowed. Retrieval pulls per-workspace context within budget. The agent dispatches to a local Qwen3 27B. The synthesis report cites each fact with [acme-news:doc-id] or [acme-user:doc-id]. The audit log captures the full operation.
Memory beyond vector RAG
The memory stack now has three layers. Vector RAG over pgvector sits alongside entity-graph memory with provenance and temporal validity (new nodes and edges tables, pgvector for embeddings) and session/working memory (per-user persistent preferences and in-flight context). The three layers serve different lifetimes: fast lookup over content, structured durable knowledge with provenance, and per-user state surviving across turns. A working conversational agent needs all three.
A consolidation pass between sessions distills durable facts from the previous session into the entity graph. The process is idempotent: the consolidator checks list_entities and query_graph before the LLM call, so a re-run produces no duplicates. The pattern is Anthropic’s “Dreaming.” Mem0 and Letta integrations swap in behind the abstraction for teams that already standardized on those.
Open-weights as serious deployment
v3.4 generalised what v3.3 started. engines.yaml adds Llama 4, Qwen3, DeepSeek-V3, and Mistral Large alongside the Gemma 4 entries. These are the four families that became serious local agent defaults in 2026. Qwen3 27B is the practical recommended balance for Apple Silicon with the MLX backend. Gemma 4 entries are updated with notes on the Ollama 0.19 MLX backend’s ~2x decode speedup. A Fortune 500 CISO who needs AI capability inside a controlled network can read the sizing matrix at docs/open-weights-sizing.md and pick a deployment configuration in one sitting.
Behind model selection sits an LLM-backend abstraction. The default routes through LiteLLM for breadth of provider coverage; a direct backend calls each provider’s official SDK (anthropic, openai, google-genai) for users who want a smaller dependency surface. Adding a new gateway (Bifrost, Portkey, OpenRouter) is one file. Swapping providers is cheap by design, which is how the chat code path stays clean of provider-specific quirks.
OTLP and Jaeger observability
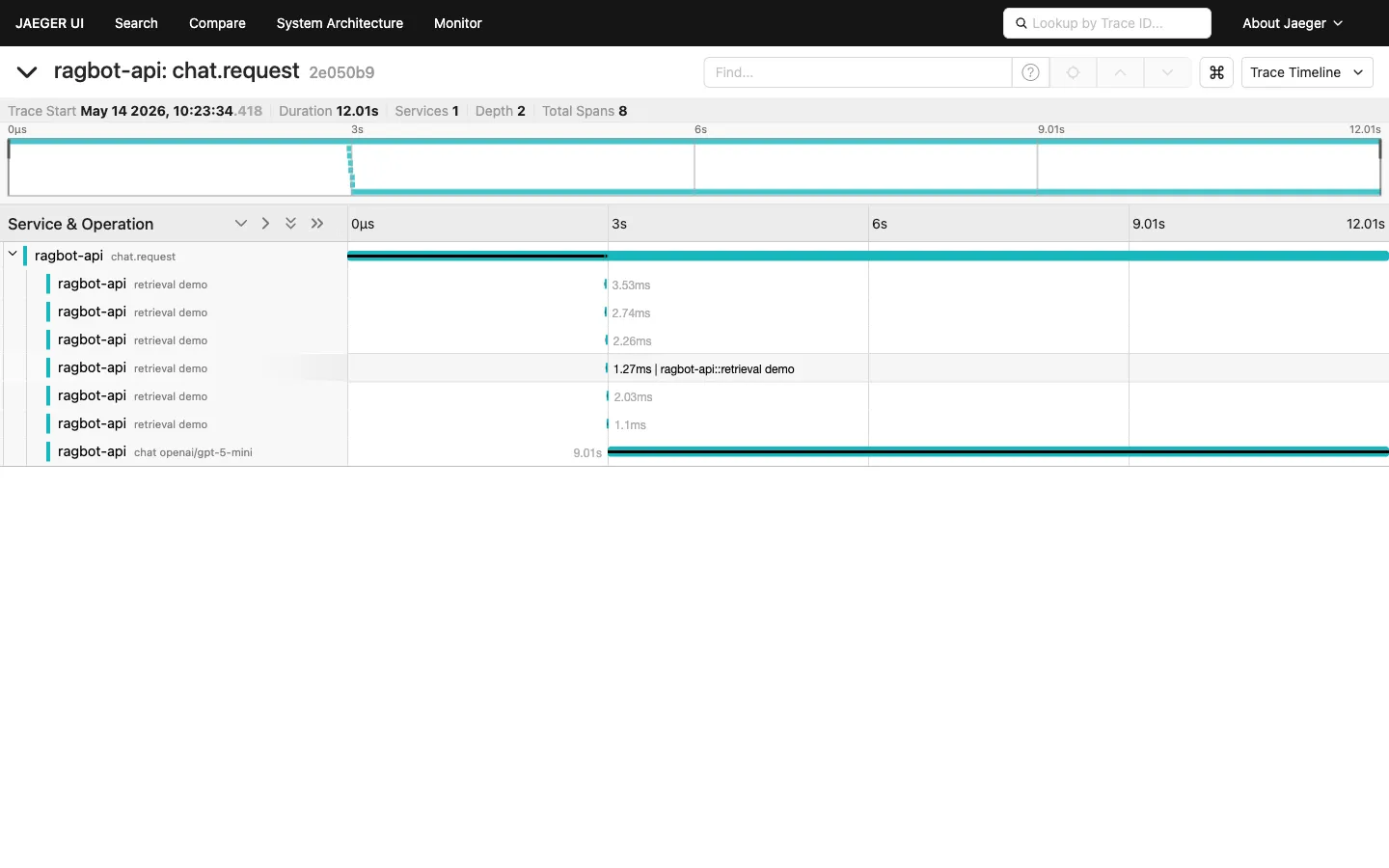
OpenTelemetry traces ship by default. Set OTEL_EXPORTER_OTLP_ENDPOINT and traces flow to Phoenix, Langfuse, Datadog, or Honeycomb. Prometheus exposition lives at /api/metrics; cache-stats JSON at /api/metrics/cache. Prompt caching with cache_control annotations on the static system-prompt prefix tracks with the 70-90% real-world cost reduction the ngrok benchmarks report on Anthropic.
The trace tree is the legibility layer for engineering leadership. A platform engineer who wants to know what one chat turn cost in time, tokens, model calls, and retrievals opens the trace and reads it. The architecture stops being implicit and becomes inspectable.
A keyboard shortcut layer
Seven shortcuts cover the 2026 expected interactions: ⌘K model picker, ⌘J workspace switch, ⌘N new chat, ⌘B background the current run, ⌘. cancel the current run, ⌘? help overlay, and ⌘/ for real message-history search (not a stub). Platform-aware key matching, with Meta on macOS and Ctrl elsewhere. Exact-modifier matching, so ⌘⌥K does not accidentally fire ⌘K. Covering the right interactions matters more than covering many.
v3.5: substrate cleanup
v3.5 shipped one day after v3.4. The next-major-features release exposed substrate-level rough edges that needed cleanup. v3.5 is the pass that does it.
The breaking change is the most visible. Qdrant is removed entirely. No shim, no opt-in path. synthesis_engine.vectorstore.QdrantBackend plus the qdrant_data/ storage path, the qdrant-client dependency, the RAGBOT_VECTOR_BACKEND env var, and the ragbot-qdrant Docker volume all go. Operators who ran v3.4 with RAGBOT_VECTOR_BACKEND=qdrant need to reindex their workspaces into pgvector before upgrading. The VectorStore ABC at synthesis_engine.vectorstore is retained so substrate consumers outside Ragbot can plug in alternative backends behind the same contract. The abstraction stays; the second concrete backend goes.
The other v3.5 changes turn the v3.4 features from “shipped” to “shipped well.” The FastAPI lifespan now constructs an AgentLoop at startup with the resolved MCP client and a filesystem checkpoint store, then registers it as the default. /api/agent/run resolves against a real loop on a fresh install; through v3.4 it returned "Agent loop is not configured", which should not have shipped.
OTLP metric and trace export are now independently configurable. OTEL_EXPORTER_OTLP_METRICS_ENDPOINT accepts the literal "none" to disable metric export, which is what the bundled docker-compose stack does (Jaeger accepts traces only). The UNIMPLEMENTED errors from earlier deployments are gone.
App-namespace logger lines now surface in docker logs ragbot-api because src/api/main.py calls logging.basicConfig before uvicorn takes over. And get_vector_store() returns None when pgvector is unreachable; callers in rag.py treat that as “RAG unavailable; chat-only mode,” so the user-facing failure mode is graceful, not a 500.
The test-suite delta tells the cleanup story in numbers. v3.4.0 ended with 871 passing, 25 skipped, 4 failing (three Qdrant tests plus one sentence_transformers environment gap). v3.5.0 is 850 passing, 14 skipped, 0 failing. Twenty-one Qdrant tests went with the backend; eleven now skip cleanly on dev installs without heavy ML dependencies.
The shift
Pull back. The three releases are facets of one change: Ragbot is now the conversational reference runtime of synthesis engineering. The methodology produces three runtimes, one per established HCI primitive. Ragbot is the conversational one. Ragenie is the procedural one (workflow definition with autonomous execution). Synthesis-console is the direct-manipulation one (browse and edit). The family is open-ended; the substrate (synthesis_engine) is now a public library that any synthesis-engineering runtime can compose. Ragenie v1.0 imports it cleanly. So can the next runtime that joins the family.
The product name stays Ragbot (sentence case, not RAGbot). Renaming a product whose feature set still said “chat with RAG” would have been marketing dressing on the same surface. The arc from v3.3 to v3.5 ships the substance first.
The architectural rationale behind the arc (the three-runtimes thesis, the discipline patterns that shaped the build, the deterministic-enforcement frame) will be in companion posts on synthesisengineering.org and synthesiscoding.org. The GitHub releases catalog what shipped: v3.3.0, v3.4.0, v3.5.0. This post is the narrative companion to all three.
If you want to try it: RAGBOT_DEMO=1 docker compose up -d against the bundled demo workspace. Install steps are at github.com/synthesisengineering/ragbot/blob/main/INSTALL.md.